Welche Rolle spielt der PageRank – ein ursprüngliches Konzept für die Einschätzung der Wichtigkeit von Websites für die Google-Suche heute noch?
Von Experten hört man unterschiedliche Meinungen. Tatsache ist, dass Google immer noch PageRanks für jede Website ermittelt und diese auf Wunsch auch zur Verfügung stellt, zum Beispiel mit der Google Toolbar. In der Skriptgalierie bei Google Drive (früher Docs) gibt es einige Scripts, die für eine Domain den PageRank abfragen.
Der PageRank als Spiegel der „Wichtigkeit“ einer Domain?
Der PageRank, den Google für Webseiten ermittelt basiert auf einem Algorithmus, der die Verlinkung von Webseiten untereinander bewertet. Grundlage dafür ist das theoretische Modell eines zufälligen Surfers („random walk plus teleport“ gemäß einer Markov-Kette) , das mit Hilfe des Web-Graphs operationalisiert wird. Der Web Graph enthält die Verbindungen der verschiedenen Seiten untereinander. Der PageRank spiegelt dann in einem numerischen Wert das „Gewicht“ einer Site wider und dient bei der Entscheidung dazu. welche Seite auf der Suchergebnisseite wie angezeigt werden soll, als Kriterium, um die „Wichtigkeit“ der in Frage kommenden Seiten abzuschätzen.
Entsprechen sich PageRank und Sichtbarkeitsindex?
In wie weit hängt der PageRank nun mit der konkreten Suchmaschinenergebnisseitenposition zusammen? Dafür müsste man ein anderes Kriterium haben.
Ich vergleiche das mal mit einem Sichtbarkeitsindex. Der Sichtbarkeitsindex wird mit einer anderen Methode berechnet und dient vor allem Suchmaschinenoptimierern dazu, Sites konkret hinsichtlich der Auftretenswahrscheinlichkeit in den Sucherergebnisseiten bei der Eingabe vieler verschiedener Keywords einzuschätzen.
Praktisch läuft die Ermittlung so: Man schickt viele Hunderttausend häufig verwendete Suchkeywords als Suchanfrage an Google und ermittelt aus den Ergebnisseiten die Sites, die jeweils für ein Keyword ausgegeben werden. Das liefert einen Sichtbarkeitsindex für eine Domain.
Für die Untersuchung habe ich den SVR (Seolytics Visibility Rank) der Firma Seolytics verwendet. Die Daten stammen aus der zweiten Kalenderwoche des Jahres 2013. Die PageRank-Werte stammen aus einer Schnittstelle von Google.
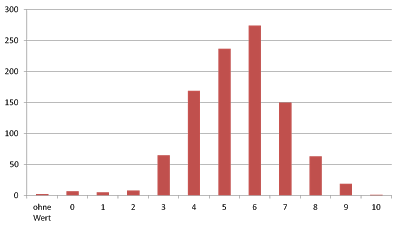
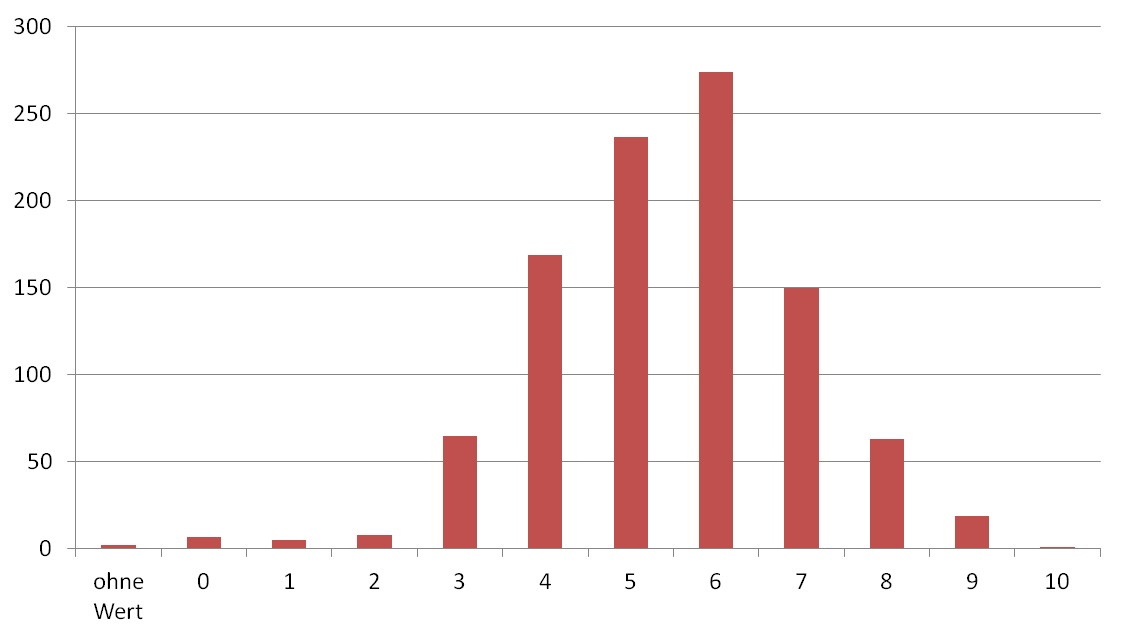
PageRank-Werte von 5 und 6 dominieren in der Spitzengruppe der Webseiten in Deutschland
Wenn man sich die PageRank-Wert-Verteilung (die ganzen Zahlen dafür, die Google bereitstellt) mal ansieht, erkennt man, dass unter den 1000 „sichtbarsten“ Sites die meisten Sites einen PageRank von 5 oder 6 haben (etwas über die Hälfte). Ich persönlich hätte erwartet, dass in den Top 1000 Websites nach Sichtbarkeit 7er, 8er und 9er PageRank-Werte dominieren, während 1er gar nicht und 2er so gut wie nicht auftreten. Das war meine Annahme. Dem ist nicht so.
Hier die Ausgabe in Zahlen:
FREQUENCIES
/VARIABLES= PR
/FORMAT=AVALUE TABLE
/HISTOGRAM=NONORMAL PERCENT.
PR
+———–+—–+———+——-+————-+———–+
|Value Label|Value|Frequency|Percent|Valid Percent|Cum Percent|
#===========#=====#=========#=======#=============#===========#
| | 0| 9| ,90| ,90| ,90|
| | 1| 5| ,50| ,50| 1,40|
| | 2| 8| ,80| ,80| 2,20|
| | 3| 65| 6,50| 6,50| 8,70|
| | 4| 169| 16,90| 16,90| 25,60|
| | 5| 237| 23,70| 23,70| 49,30|
| | 6| 274| 27,40| 27,40| 76,70|
| | 7| 150| 15,00| 15,00| 91,70|
| | 8| 63| 6,30| 6,30| 98,00|
| | 9| 19| 1,90| 1,90| 99,90|
| | 10| 1| ,10| ,10| 100,00|
#===========#=====#=========#=======#=============#===========#
| Total| 1000| 100,0| 100,0| |
+—————–+———+——-+————-+———–+
Nun fand ich es spannend zu sehen, ob es einen Zusammenhang zwischen PageRank und Sichtbarkeitsindex gibt.
Gibt es einen linearen Zusammenhang von PageRank und Sichtbarkeitsindex?
Ich fand keinen. Ich habe eine lineare Regression von Sichtbarkeitsindex auf PageRank ermittelt und einen Zusammenhang von r = .13 ermittelt. R hoch 2 ist also noch nicht mal .02. Der Sichtbarkeitsindex erklärt also nur knapp 2 Prozent der gemeinsamen Varianz von Sichtbarkeitsindex und PageRank – und das ist wenig! Mit anderen Worten: Der PageRank sagt also nicht die Sichtbarkeit in Google voraus.
Das zeigt sich auch ganz augenscheinlich, wenn man die Tabelle mit den Werten durchsieht. Es gibt in der Spitzengruppe der sichtbarsten Seiten (Top 20) nicht nur hohe PageRanks. Der schlechteste war 5, der höchste 9.
Auch im Mittelfeld um Platz 500 herum tummeln sich 5er, 6er, 7er und 8er Pageranks. Und auch am Tabellenende von Platz 950 bis 1000 findet man gar nicht selten hohe PageRank-Werte.
Hier ist die Ausgabe aus PSPP (einer OS-Alternative von SPSS)
REGRESSION
/VARIABLES= SVR
/DEPENDENT= PR
/STATISTICS=COEFF R ANOVA.
Model Summary
#====#========#=================#==========================#
# R #R Square|Adjusted R Square|Std. Error of the Estimate#
##===#========#=================#==========================#
#|,13# ,02| ,02| 1,53#
##===#========#=================#==========================#
ANOVA
#===========#==============#===#===========#=====#============#
# #Sum of Squares| df|Mean Square| F |Significance#
##==========#==============#===#===========#=====#============#
#|Regression# 39,00| 1| 39,00|16,71| ,00#
#|Residual # 2329,06|998| 2,33| | #
#|Total # 2368,06|999| | | #
##==========#==============#===#===========#=====#============#
Coefficients
#===========#====#==========#====#======#============#
# # B |Std. Error|Beta| t |Significance#
##==========#====#==========#====#======#============#
#|(Constant)#5,43| ,05| ,00|111,21| ,00#
#| SVR # ,00| ,00| ,13| 4,09| ,00#
##==========#====#==========#====#======#============#
Hat der PageRank also keinen praktischen Wert (mehr)?
Die PageRank Idee scheint mir dennoch ein Qualitätsmerkmal zu sein und kann offensichtlich das sehr gut abbilden, was er modellhaft abbilden soll: Die Wahrscheinlichkeit, mit der ein zufälliger Surfer über die Site kommt oder anders ausgedrückt, wie „beliebt“ im Sinne von nutzwertig, notwendig und allgegenwärtig eine Domain ist. Wie reliablel das abgesehen vom Augenschein ist, weiß ich nicht. Dafür bräuchte man noch ein anderes Kriterium.
Einige Arbeiten versuchen PageRank mit dem Webseiten-Qualitätsaspekt „Verlässlichkeit“ in Verbindung zu bringen, wie zum Beispiel diese Studie von Sondhi et al an der Universität Illinois, USA.Die Wissenschaftler nahmen dafür Websites aus dem Themenbereich Medizin ins Visier, weil sich auf solche Seiten der etablierte HONcode anwenden lässt, mit dem sich medizinische Publikationen qualitativ bewerten lassen. Die Autoren haben das Konstrukt der Akkuratheit entwickelt (und ein formelmäßiges Maß dafür gefunden als Angabe der Größe einer Abweichung zwischen Website-Beurteilung nach HON und Google PageRank), um zu bemessen, wie gut sich aus dem PageRank Algorithmus die Verlässlichkeit von Informationen auf medizinischen Webseiten voraussagen lässt. Die Autoren sprechen von einer Akkuratheit von 80 Prozent. Anders ausgedrückt: Google PageRank-Wert und der Evaluierung einer Website nach HON konvergieren deutlich.
Hoher PageRank – Website mit zuverlässiger Information
Daher würde ich mich zu der Meinungsaussage hinreißen lassen: Für informationssuchende Webuser ist der PageRank auch heute noch ein verlässlicher Indikator: Hoher PageRank heißt verlässliche Informationen auf der Seite.