
Oft habe ich den Eindruck, Podcast-Produzenten wissen einfach nicht, wie viele Leute ihre Episoden hören. Sehr grob werden da Hörerzahlen in den Raum geworfen. Manchmal bescheidet man sich mit 3.500 bis 10.000 Hörern pro Episode, gern fallen aber auch mal Werte um 150.000.
Diese Zahlen dürften auf Schätzungen und Hochrechnungen beruhen. Hat man Zugriff auf einen Webserver und hostet die Audiodateien da, hat man in der Regel auch Zugang zu den Protokolldateien, den Logfiles. Diese kann man gezielt auswerten, um die Abfrageanzahl pro Datei zu ermitteln. Excel oder andere Analysetools leisten hier wertvolle Hilfe. Wir versuchen das mal mit Excel.
Anders als bei der klassischen Webanalyse gibt es kaum standardmäßge Analysetools, um die Nutzung von On-Demand-Audio-Content zu erfassen.
Auch im Rundfunkbereich, im klassischen Radio, ist die Ermittlung der Anzahl erreichter Hörer hinreichend problematisch. In diesem Sektor versucht man, mittels groß angelegter Umfragen die Hörerzahl zu ermitteln. Die Daten basieren weitgehend auf der Erinnerungsfähigkeit der befragten Personen. Die kleinste zeitliche Einheit ist eine viertel Stunde. Im Zuge einer Erhebung werden die Befragten gebeten, alle 15 Minuten ihre Mediennutzung zu protokollieren.
Wie misst man die Nutzung von Audiomedien?
Versuche der elektronischen, nicht reaktiven Erfassung, z.B. durch eine Armbanduhr, die die Umgebungsgeräusche einschließlich eventuell vorhandener Radioklänge scannt, sind gescheitert.
Ein sehr breit angelegtes populäres Radioprogramm wie WDR 1Live (NRW) kommt auf durchschnittlich etwas mehr als eine Million Hörer pro Stunde (6 bis 18 Uhr) nach dieser Erhebungsmethodik. Ein auf eine Stadt begrenzter Sender kommt typischerweise auf 30.000 bis 40.000 Hörer pro Stunde.
Allerdings muss man hier die leichte Zugänglichkeit und die Gewohnheitseffekte mit einbeziehen.
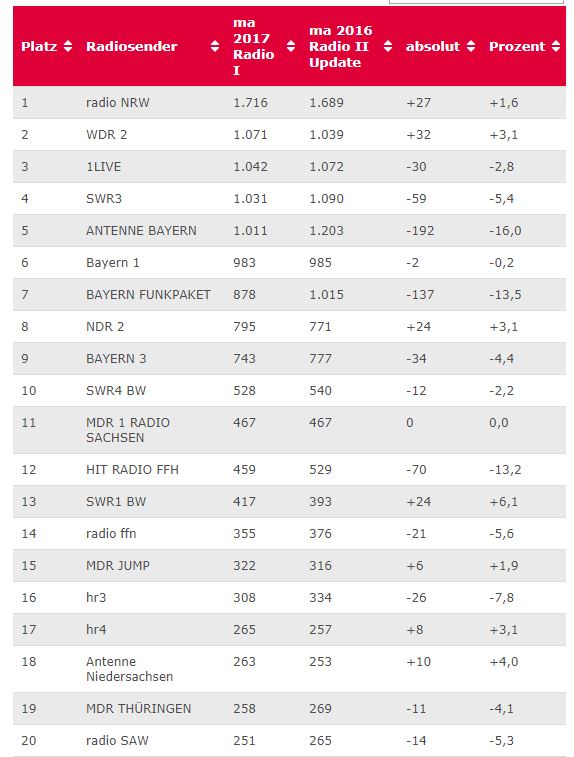
Dabei fällt auf: Unter den 100 reichweitenstärksten Radiosendern in Deutschland gibt es nur Musikprogramme, auch wenn manche einige Talkelemente und längere Talkstrecke einbauen.
Das kann man auf zweierlei Arten interpretieren: Entweder lässt die deutsche Radiolandschaft eine wahnsinnige Lücke und die Hörer wollen Leute reden hören, was aber nicht erfüllt wird oder es gibt nicht wirklich so viele Podcasthörer, so dass diese sich pro Episode gleich in 10.000er Schritten messen lassen könnten.
Klar ist aber auch, dass man die großen Zahlen der per Demoskopie erhobenen Reichweiten auch ernstlich in Zweifel ziehen kann. Eignet sich das Verfahren noch, um die Realität abzubilden? Darüber wird in einschlägigen Foren heftig diskutiert.
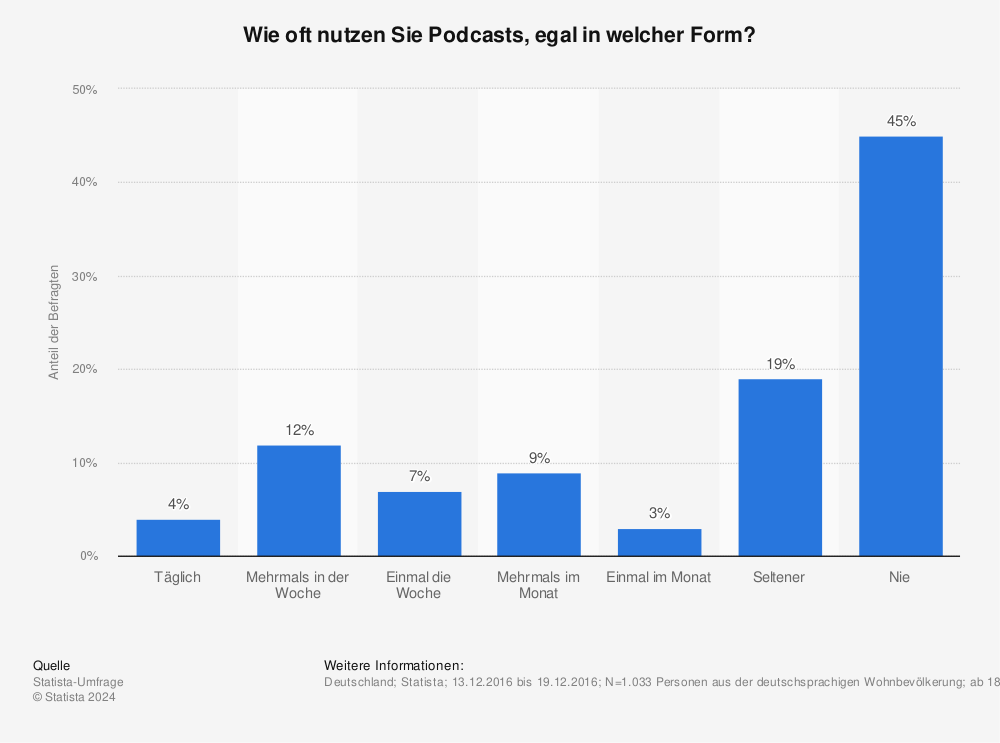
Mit dem gleichen Instrumentarium kann man auch versuchen, Podcasthörer zu erfassen. Das hat man auch tatsächlich getan und ermittelt damit Hörer- und Nutzerzahlen in der Größenordnung von 7,5 Millionen in Deutschland.
Quelle: Statista
In dieser Grafik erscheint die Säule „nie“ überwältigend hoch. Allerdings heisst dies, 55 Prozent der Befragten hören Podcasts täglich, mehrmals pro Woche einmal im Monat oder seltener.
Ähnliche Daten zeigt die ARD/ZDF-Onlinestudie in Bezug auf Podcasts.
Die Podacst-Anbieterlandschaft ist sehr heterogen.
Podcast-Hörerzahlen für einen Podcast kann man technisch sehr gut messen
Im Prinzip gibt es zwei Ansätze, um die Anzahl der Hörer pro Podcast-Episode zu schätzen.
Man versucht über die Interaktion auf Web- oder App-Oberflächen eine Vorstellung davon zu gewinnen, ob ein Audioelement abgerufen wird. Man könnte also über Javascript oder ähnliche Frontendscriptsprachen zählen, wie oft der Play-Button gedrückt wird – und entsprechend der Pause- oder Stop-Button.
In ähnlicher Weise könnte man feststellen, wie oft ein Beitrag gesucht, gefunden und in der Suchergebnisliste geklickt wird. Oder man versucht die Anzahl an Bewertungen und Likes etc. als Maßstab heranzuziehen. All das dürfte hinreichend ungenau sein.
Ich bin sicher, viele Angaben, die einige Podcaster so in die Diskussion werfen, beruhen auf dieser oder einer ähnlichen Herangehensweise. Wahrscheinlich werden die Zahlen übertrieben, genau wie die Anzahl an Ad Impressions in der Online-Branche immer übertrieben worden ist bis sich herausstellte, dass man auch Bannereinblendungen mitzählt, die kein Mensch sieht. Diese systematischen Überschätzungen gehören wohl zum Handwerkszeug, tun aber eigentlich niemandem gut.
Aussagekräftiger scheint es mir zu sein, wenn man herauszufinden kann, wie oft eine Datei – eben eine Audiodatei im m4a- oder mp3-Format vom Server abgerufen und übermittelt wird.
Die meisten Podcastanwendungen rufen die angeforderten Audiodateien nach Bedarf ab. Das Szenario: Der Nutzer kommt über eine Suche oder einen externen Link auf die Verknüpfung in iTunes oder Stitcher. Er oder sie möchte die Datei abspielen, sich eine Episode anhören, so dass die Anwendung auf dem Endgerät den Server kontaktiert, auf dem die Audiodatei tatsächlich liegt.
Das kann ein anderer Dienst sein wie Soundcloud oder es kann ein eigener Linuxserver sein, auf dem ein Webserver läuft. Dies ist für eine genauere Analyse sicherlich die beste Voraussetzung, da man dann Zugriff auf die Protokollierungsdateien des Webservers hat, auf die sogenannten Logfiles.
Der sehr gebräuchliche Apache-Webserver protokolliert standardmäßig jeden einzelnen Zugriff auf Dateien in diesen Logfiles, sofern der Administrator dies nicht ausgeschaltet hat. Meist werden diese Rohdateien aus ökonomischen oder datenschutzrechtlichen Gründen nur eine bestimmte Zeit lang vorgehalten. Die Logfiles werden geschrieben, egal, ob es sich um ein Webhosting-Produkt handelt, auf dem die Daten liegen oder auf einem Cloud-Server. Manchmal ist das Logging ausgeschaltet, zum Beispiel auf dem S3-Service von Amazon AWS. Hier ist beschrieben, wie es aktiviert werden kann.
Logfiles sind im Grunde einfache Textdateien, die man sich mit einem Texteditor wie Notepad++ oder auch dem Editor von Windows ansehen kann. Je nach Nutzungsintensität können diese Dateien allerdings sehr groß sein.
Jede Aktivität des Servers wird hier festgehalten, also auch die Anforderung einer Audiodatei durch eine Webseite, eine App oder eine andere Anwendung auf einem Gerät wie Apple TV. Dies ist der Ansatzpunkt für eine Zählung: Wie oft wurde eine Audiodatei in einem Zeitraum mit http-Get angefordert – und mit welchem Ergebnis?
Leider kann man Anforderung und Nutzung (also das Anhören) nicht 1:1 gleichsetzen. Wenn man Podcasts abonniert, schaut die Anwendung in regelmäßigen Abständen nach, ob sich der Feed geändert hat, der den Podcast beschreibt.
Wenn er sich ändert, ist eine neue Episode erschienen und der Beitrag wird ohne weitere Userinteraktion heruntergeladen, damit der Nutzer sich die Audiodatei anhören kann und nicht über das Mobilfunknetz zugreifen muss, wenn er im Auto, in der Bahn, im Bus oder wo auch immer diese neue Episode anhören möchte.
Nach der Veröffentlichung einer Podcastepisode wird man also zahlreiche Downloads registrieren. Dies kann einen Hinweis auf die Anzahl der Abonnenten geben. Allerdings kann man nicht davon ausgehen, dass tatsächlich kurz nach dem Hochladen und Neugenerieren des Podcastsfeed alle Downloads abgefrühstückt werden. Es dauert ehe die Endgeräte diese Änderung registrieren (sie sind ausgeschaltet, die App ist nicht aktiv oder der Feed-Abruf ist nicht so hoch frequentiert). Nach meiner Erfahrung zieht sich der Download durch die Abonnenten immer etwas hin. Wenn die Geräte gerade nicht im WLan sind, ziehen sie sich die Datei normalerweise auch nicht. Dem User wird dann meist nur signalisiert, dass eine neue Episode erscheinen ist. Er oder sie kann dann entscheiden, ob das wertvolle LTE-Inklusivvolumen dafür eingesetzt werden soll oder nicht.
Wenn man eine Logdatei in einem Texteditor aufruft, wirkt die Darstellung sehr unstrukturiert. Allerdings täuscht das. Die Daten sind sehr strukturiert.
Jede Serverbetriebssystemvariante schreibt die Einträge leicht unterschiedlich, aber letztlich ist immer wieder die folgende Anordnung anzutreffen. So sieht eine Zeile, also ein einzelner Logfile-Eintrag aus:
54.193.xxx.yyy - - [03/Dec/2017:19:54:25 +0100] "GET /podcasts/feed.xml HTTP/1.1" 200 96860 "-" "Go-http-client/1.1"
Welche Informationen stecken da drin?
Von links nach rechts gelesen finden wir, getrennt jeweils mit Leerzeichen folgenden Angaben:
- die IP-Adresse (oben im Beispiel anonymisiert)
- danach folgen zwei in der Regel unbelegte Spalten, repräsentiert mit dem Zeichen „-“
- Datum in eckigen Klammern im Format Tag, Monat, Jahr, Stunde, Minute, Sekunde und Zeitzone
- Anforderung (request) in Anführungszeichen mit Angabe des Pfades und der Datei, angehängt wird das Protokoll, hier http/1.1
- Ergebniscode, den der Server generiert. 200 bedeutet OK.
- Datenmenge in Bytes
- Falls mitgeteilt, der Referrer in Anführungszeichen, ansonsten steht hier wieder das Zeichen „-“
- User-Agent (hieraus gewinnt man auch einige Informationen über den anfragenden Client)
In diesem Beispiel sieht man also, dass am 3.12.2017 um 20:54 Uhr MEZ jemand – wahrscheinlich ein Gerät automatisch – mit einer Anwendung, die vermutlich mit der Programmiersprache Go realisiert wurde auf die 97 KB große Datei „feed.xml“ zugegriffen hat und diese Datei erhalten hat.
Auf diese Weise findet man auch heraus, wie oft erfolgreich auf eine bestimmte Audiodatei (Format üblicherweise mp3 oder m4a) zugegriffen wurde.
Wir müssen also wissen, welchen Namen die Audiodatei hat. Dann kann man zum Beispiel mit Notepad++ kurz einmal danach suchen und die Anzahl der Vorkommen in der Logdatei zählen lassen.
Wesentlich bequemer ist es, die Analyse mit einem Programm wie Excel, R, SPSS (oder dem open-Source-Pendant PSPP) auszuführen. Auch Google Docs eignet sich und kostet nichts.
Bei den Logfiles handelt es sich um einfache Textdatei. Viel Filterung beim Importieren ist nicht notwendig. Bei Excel würde der Importvorgang so aussehen:
- Datei von Server herunterladen, per FTP oder SCP (Shell, SSH).
Man findet diese Logfiles meist eine Ebene über dem Document Root in einem Verzeichnis namens „logs“ oder ähnlich. - In Excel in einer leeren Tabelle auf Zelle A2 klicken, damit der Import hier beginnt. Die erste Zeile bleibt leer. Hier muss später die Überschrift hinein. Menüpunkt „Daten“ klicken.

In Excel den Tab „Daten“ klicken und „Aus Text“ wählen. - „Aus Text“ wählen
Die gewünschte Datei im Dialogfenster wählen und importieren. Wenn die herutnergeladene Datei nicht sichtbar wird, den Dateifilter anpassen auf „*.*“ oder nach „*log*“ filtern.
Logfiles haben oft keine Dateiendung. Daher sollte man den Filter anpassen. - Im folgenden Dialog die Option „Getrennt“ wählen, nicht „feste Breite“ und weiter klicken.
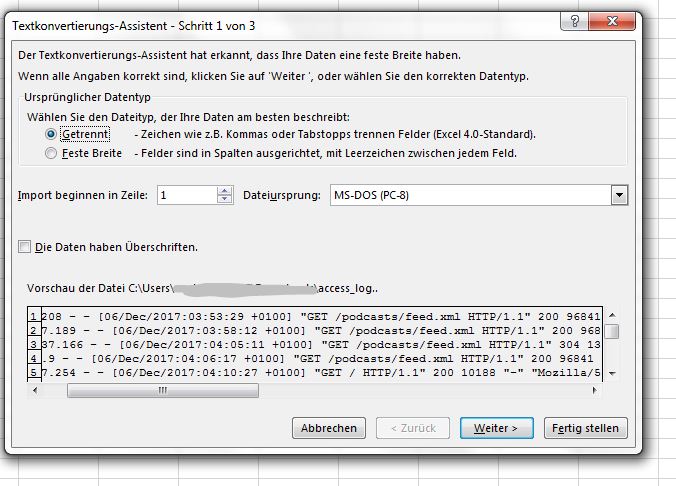
Die Daten der Logfileeinträge sind mit Leerzeichen getrennt. Das Zeichenformat ist ASCII - Im nächsten Schritt „Leerzeichen“ als Trennzeichen wählen. Wenn man will, kann man auch die öffnende eckige Klammer ( [ ) als Trennzeichen angeben. Das Datum wird dann von der Zeitzone abgegrenzt. Bitte darauf achten, dass der Textqualifizierer angegeben ist, damit die Zeichenkette für den Request nicht durchschnitten wird. Dann auf weiter klicken.
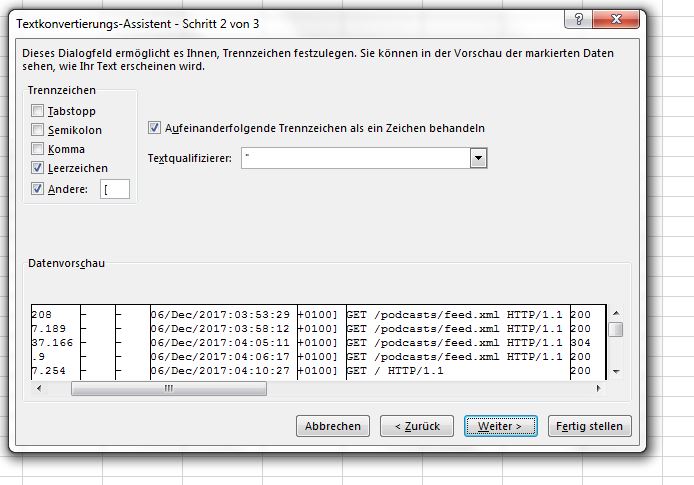
Die Daten der Logfileeinträge sind mit Leerzeichen getrennt. Das Zeichenformat ist ASCII - Die erste Spalte nicht als Standard, sondern als Text importieren. Sonst macht Excel aus der einen oder anderen IP Adresse ein Datum. Das ist störend beim Filtern und Pivotisieren.
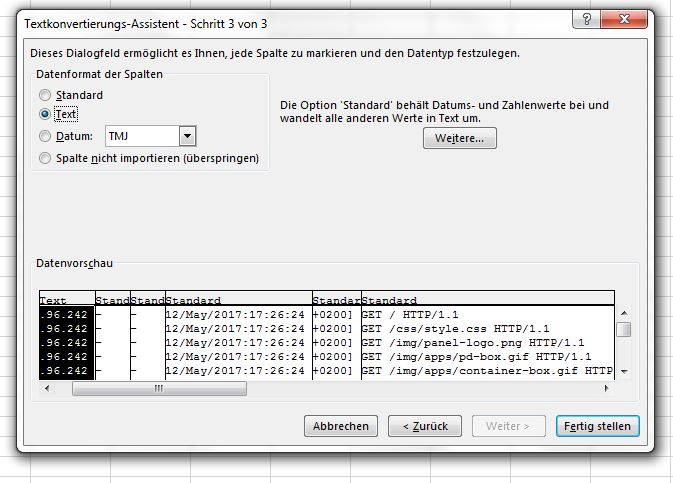
Die IP-Adresse sollte als Text importiert werden, damit die Zeichenkette nicht falsch interpretiert wird. - Nun noch den Import fertigstellen. Das letzte Dialogfenster mit OK bestätigen.
- Nun sollte die Datei importiert sein. Spalte B und C kann man löschen.
Wer will, kann mit geeigneten Formeln die Datumsangabe umformen, um zeitliche Abgrenzungen besser vornehmen zu können. Excel erkennt dieses Format nicht.
Das richtige Datumsformat erzeugen
Man braucht eine Formel, die die Datumsinformationen in ein in Excel verwendbaren Format schreibt. Störend ist vor allem die englische Benennung der Monate mit einer deutschen Excelversion. Man müsste also die Monatsnamen mit den deutschen Entsprechungen ersetzen. Dann erkennt Excel das Datum und man kann beispielweise nach Zeiträumen filtern. Dies überspringen wir hier. Man könnte das dadurch lösen, dass man manuell den Datumsbereich ausschneidet und in eine extra Tabelle kopiert.
Die richtigen Informationen zur Podcast-Episoden-Datei finden
Beim Suchen nach den Einträgen im Logfile, die die Dateizugriffe auf Audioinhalte dokumentieren, sollte man nicht nur den Namen kennen, besser auch den Speicherort, also die Pfadangaben.
In dem von mir verwendeten Contentmanagementsystem werden die Dateien unter podcasts/media abgelegt und der Request sieht so aus
37.24.xxx.yyy 20/May/2017:19:24:53 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 2339 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de)
Allerdings erkennt man, dass die große Audiodatei nicht auf einen Schlag heruntergeladen wird, sondern in Teilen. Der Server antwortet nicht mit dem Code 200, sondern mit 206. Das steht für „partial content“, also einen teilweisen Download.
Wenn die Audiodatei angehört wird, wird nur der jeweils nächste Teil geladen. Wir die Datei komplett geladen, ist der letzte Eintrag mit dem Statuscode 200 („OK“) versehen.
Der Download einer Datei besteht also in der Regel aus mehreren Einträgen im Logfile und sieht so aus, beispielsweise:
37.24.xxx.yyy 20/May/2017:19:24:53 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 2339 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de) 37.24.xxx.yyy 20/May/2017:19:25:08 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 13741009 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de) 37.24.xxx.yyy 20/May/2017:19:25:49 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 164526 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de) 37.24.xxx.yyy 20/May/2017:19:24:53 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 1851869 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de) 37.24.xxx.yyy 20/May/2017:19:25:03 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 5519437 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de) 37.24.xxx.yyy 20/May/2017:19:25:06 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 206 782985 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de) 37.24.xxx.yyy 20/May/2017:19:25:49 GET /podcasts/media/2017-05-12_podcast2017_folge_0.mp3 HTTP/1.1 200 5850240 - AppleCoreMedia/1.0.0.14E304 (iPhone; U; CPU OS 10_3_1 like Mac OS X; de_de)
Diesen Block könnte man als einen Hörer interpretieren.
Wir wissen aus den Logfiles nicht mit Sicherheit, ob es sich um einen Abonnenten gehandelt hat und die Datei deswegen heruntergeladen wurde, oder ob der User sich das zeitgleich anhörte. Wir könnten uns nur ansehen, wie die Downloads der einzelnen Blöcke zeitlich auseinanderliegen.
Es handelt sich in diesem Beispiel um einen Abstand im Sekundenbereich. Also darf man interpretieren, die Datei wurde im Rahmen eines Abonnements geladen. Das zeigt auch er user-Agent Eintrag „AppleCoreMedia“. Es handelt sich um ein iPhone mit IOS 10.3.1.
Es werden sich in der Logdatei sehr viele solcher Einträge finden.
Wir müssen also diese Einträge auf einen Betrachtungszeitraum über die Datumsangabe begrenzen, passend mit dem Pfad- und Dateinamen filtern und dann Mehrfacheinträge anhand identischer IP-Adressen zu einem zusammenfassen.
Das geht mit der Pivot-Funktion in Excel sehr gut. Um sich das Leben leichter zu machen, kann man die vorgefilterte Tabelle kopieren und die Werte in einer neuen Tabelle einfügen, die dann Grundlage für die Pivot-Darstellung ist. Ich würde empfehlen, dabei alle mp3- oder m4a-Dateien zu filtern, nicht nur eine Datei. So kann man dann das Request-Feld als Filter benutzen und sich mehrere Dateien ansehen.
Um an die oben dargestellten Importschritte wieder anzuknüpfen: Wenn man eine Pivotdarstellung mit Excel ausführen möchte, muss man in die freigelassene erste Zeile A nun Überschriften für jede Spalte schreiben, zum Beispiel A: IP Adresse, D: Datum, E: Zeitzone, F: Request, G: Code, H: Bytes, I: Referrer, J: User-Client.
Setzt man nun den Curor in die Zelle A1, in der „IP Adresse“ steht, kann man die Pivotdarstellung erzeugen, und zwar mit „Einfügen“ > „Pivot Table“. Der entsprechende Bereich sollte automatisch korrekt markiert werden. Eine neue Tabelle als Ziel wird angelegt.
Wir wollen nach IP-Adresse pivotisieren. Also ziehen wir das Feld „IP Adresse“ in den Bereich „Zeilen“ der Feldliste. Das Feld „Request“ nutzen wir als Filter und ziehen es in den Bereich Filter.
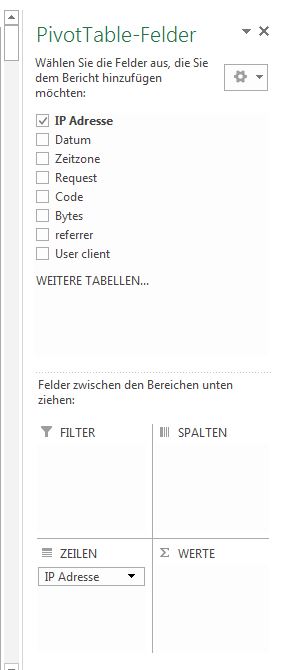
Das Feld „Bytes“ nutzen wir um die Summe der Datenmenge pro IP-Adresse zu ermitteln und ziehen es in den Bereich „Werte“. Außerdem ziehen wir „Codes“ in den Bereich „Werte“ und lassen uns aber nicht die Summe, sondern die jeweilige Anzahl der Codes anzeigen. Dies geht mit „Wertfeldeinstellungen“. Dazu klickt man auf den kleinen Pfeil nach unten, dort wo jetzt noch „Summe von Code“ steht.
Über den Filter können wir nun eine mp3 oder m4a-Datei auswählen.
Leider kann man im Pivotfilter keine Text-Filteroptionen wie „enthält“ oder „endet mit“ verwenden wie in den anderen Excelfiltern.
Das Ergebnis sieht dann exemplarisch so aus:
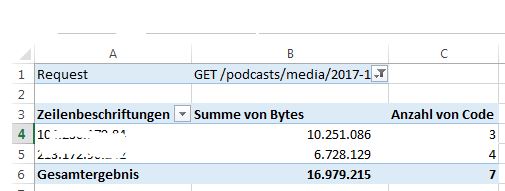
In diesem Beispiel finden wir zwei IP-Adressen mit einem 10,3 MB umfassenden Download mit drei Teilabfragen und 6,7 MB Download mit vier Teilabfragen.
Als Wert-Argument reicht es, wenn man die Anzahl der Status-Codes zählt. Wir wollen ja nur wissen, wie viele IP-Adressen eine Audiodatei angefordert haben. Die Anzahl entnehmen wir der Pivot-Liste. Dies ist dies Anzahl der Hörer bzw. der mindestens teilweisen Downloads und ein aus meiner Sicht recht harter Wert.
Man könnte hier noch tiefer hineinsehen, indem man feststellt, ob der letzte Eintrag auf eine Audiodatei von einer IP tatsächlich mit Status 200 beantwortet wurde. Wenn nicht, kann man davon ausgehen, dass die Datei nicht komplett geladen wurde.
Oder man addiert das Datenvolumen, das ja in der Logdatei ebenfalls dokumentiert ist und vergleicht dies mit der bekannten Größe der gesamten Datei. Daher habe ich im obigen Beispiel das Feld „Bytes“ in den Wertebereich der Pivottabelle genommen und die Summe ausgegeben.
Dies zu Fuß zu tun ist natürlich etwas aufwendig. Man könnte sich aber vorstellen, diese im Prinzip einfachen Aufgaben mit einem Stück Python in R zu automatisieren, um sich wöchentlich oder monatlich einen Report schicken zu lassen. Man könnte auch eine KI darauf trainieren, unvollständige oder vollständige Downloads zu erkennen.
Liegt die Datei auf Soundcloud, funktioniert das Verfahren so leider nicht. Dafür bietet Soundcloud ja eigene Abrufstatistiken, genau wie Stitcher. Das ist bequem, man kann aber diese Zahlen nicht mehr hinterfragen und auf Rohdaten hat man keinen Zugang.
Das gilt genauso für Podcast-Apps wie die von Apple in IOS oder Spotify, Auch hier gibt es grafisch aufbereitete Abruf- und Nutzungsstatistiken, die zusätzlich noch Einblicke in das Hörverhalten liefern wollen und Aussagen darüber zulassen, wann User die Episode im zeitlichen Verlauf abbrechen, wie groß die kummulierte Userschaft ist oder wie viele Abonennten oder Follower ein Podcast hat.
Fazit
Insgesamt glaube ich, dass man die Hörerzahlen vereinheitlicht messen muss, um aussagekräftige, glaubwürdige und verlässliche Hörerzahlen zu ermitteln, wenn man sich als Werbeträger etablieren möchte.
Dafür wäre ein einheitliches Modell analog der Druckauflagenermittlung im Printsegement notwendig. Eine Institution müsste diesen Ermittlungen ein Glaubwürdigkeitsiegel verleihen, so wie die IVW dies mit Magazinen und Zeitungen tut.
Dabei stellt sich allerdings die Frage, ob man tatsächlich top-down vorgehen muss. Reicht es nicht aus, sich einfach auf die Konversion zu stützen, wenn es um Werbedurchsagen geht? Gemessen werden kann dies mit Rabattcodes oder mit extra angelegten URLs, die nur für diesen Trackingzweck verwendet werden. Die wichtigen Brandingeffekte werden dabei allerdings nicht berücksichtigt.
Sicher muss man, um sein eigenes Podcastingprodukt weiterzuentwickeln auch die Informationen haben, um sinnvolle Entscheidungen zu treffen. Die Abschätzung des Interesses anhand von Zugriffs- und Nutzerzahlen gehört da natürlich dazu.
Kommentar verfassen